







25 марта 2025 года в Яндекс.Переводчик добавили тувинский язык. Он стал 10-м по счёту языком народов России, который появился в сервисах IT-корпорации. Возможным это стало благодаря нескольким энтузиастам, которые уже больше десяти лет подготавливали технологии, чтобы оцифровать родной язык.
Задолго до того, как Яндекс и Google стали внедрять в свои продукты коренные языки, несколько сотен лингвистов и айтишников в регионах и национальных республиках ужаснулись, что может стать с языками их народов в цифровом мире. Ведь тогда не было даже клавиатуры, чтобы правильно написать сообщение в соцсети на своём языке. Неравнодушные объединились в сообщества и стали работать над тем, как перенести свою культуру в диджитал.
Работу с тувинским языком возглавили iOS-разработчик Али Кужугет и филолог Чойган Ондар. Как им удалось убедить корпорации обратить внимание на их проект, что нужно для того, чтобы и ваш язык появился в онлайн-переводчиках, и ждёт ли нас коренной киберпанк — нам рассказал Али. Чойган же дополнил его историю комментариями.
глава 1
Предыстория

Али Кужугет и Чойган Ондар. Фото из соцсетей
С чего началась ваша работа по добавлению тувинского языка в Яндекс.Переводчик?
К текущему моменту я уже более 10 лет занимаюсь языковыми технологиями. В начале 2010-х годов в партнёрстве с другими тувинскими разработчиками мы создавали словарь на платформе Windows. Его мы назвали «ТывЛин» (Tuvlin).
Ещё был программист Александр Папын, он делал клавиатуру для тувинского на базе татарского языка. Там были свои минусы и плюсы, но всё равно стало очень хорошо, что люди наконец-то начали набирать тексты [на тувинском] в интернете, а не только в Word. До этого в Word был шрифт на тувинском, но как только текст копировали и вставляли в сообщение во ВКонтакте, всё съезжало.
Будучи студентом Новосибирского Государственного университета, я подумал, что люди очень мало уделяют внимания языковым технологиям. Для меня это было странно: у нас же есть институты по всей России и лингвисты, для которых было бы идеально изучать язык с помощью компьютерных систем.
Мысль об этом появилась именно в среде тувинских разработчиков?
Марийский языковой активист Андрей Чемышев из Финно-угорской лаборатории тоже в тот момент продвигал подобные идеи. Он даже намного опытнее был, какие-то вещи подсказывал мне. Были и другие компании, сообщества — башкирское сообщество, ребята из Питера, Москвы, отовсюду.
Лето 2011 года я потратил тупо на изучение технологий — учился создавать сайт с нуля. Пришёл к тому, что нужно разработать клавиатуру для Android — то есть для смартфонов. Потому что без клавиатуры люди писали тувинский текст, игнорируя тувинские буквы. Я подумал, в будущем это приведёт к тому, что в интернете все данные [на тувинском языке] будут ошибочные, непригодные для обучения искусственного интеллекта.
Приложение с клавиатурой для тувинского языка, которое Али Кужугет разработал для iOS
Как вы организовали работу над клавиатурой?
Клавиатуру на Android сделали совместно с моим коллегой из Удмуртии — Гришей Григорьевым. Выпустили приложение. Оно хорошо работало. Клавиатуру установили то ли 50, то ли 100 тысяч раз.
Потом с Андреем Чемышевым мы выпустили на базе его лаборатории установочный файл для Windows. Я придумал дизайн, как всё должно было работать, а Андрей подсказывал, как лучше. Продумали детали. Например, если нажимать комбинацию Ctrl+G получилась одна тувинская буква [символа для которой нет в русском алфавите]. Но эту комбинацию было сложно всегда нажимать. Я сделал так, что если ты мажешь пальцем по кнопке или нажимаешь не ту комбинацию, то всё равно получается нужная буква. То есть увеличил площадь нажимаемости. Благодаря этому люди стали быстрее набирать тексты.
И постепенно встал вопрос насчёт iOS. Эта система сложновата, более закрытая. Но после аспирантуры я устроился в новосибирскую компанию, где стал iOS-разработчиком. С тех пор больше 10 лет этим занимаюсь. Ну, и тувинскую клавиатуру тоже делаю, потому что каждый год она ломается из-за того, что система обновляется.
Однажды я полностью потерял код клавиатуры — у меня компьютер сломался, на котором я его хранил. Пришлось создавать всё заново, и сейчас получилось сделать более или менее хорошую версию. Также я помог алтайскую клавиатуру сделать, потом удмуртскую. В прошлом году — татарскую.
Сколько всего было сделано до проекта с Яндекс.Переводчиком!
Да, до Яндекс. Переводчика дошла куча технологий. Мы разработали клавиатуру, с её помощью удалось начать печатать тексты, сделать тувинско-русский и русско-тувинский словари.
глава 2
Процесс работы
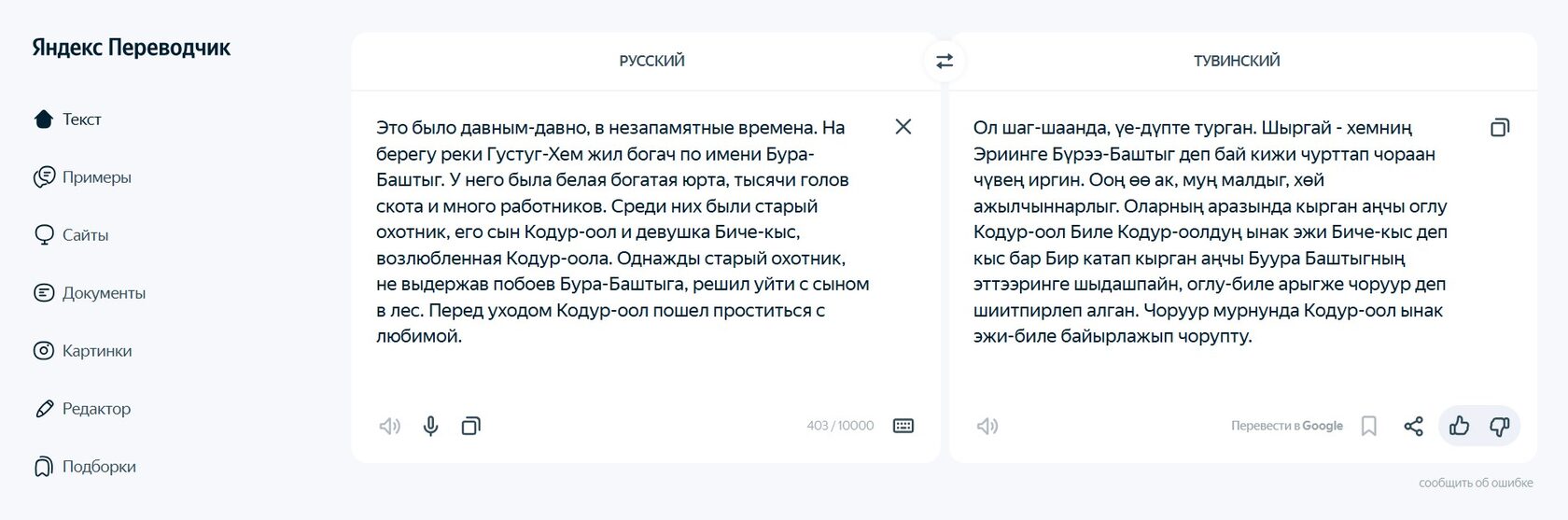
Пример перевода фрагмента тувинской сказки «Кондур-оол и Биче-кыс» в Яндекс.Переводчике
Из чего состояла работа непосредственно по добавлению тувинского языка в Яндекс?
В 2015-м я ходил в Яндекс, говорил, что вижу у них английский, русский, по-моему, ещё был казахский, татарский языки. Спрашивал, какие есть требования, чтобы добавить тувинский? И там директор именно этого направления сказал: «Миллион переводов несите, мы с радостью всё сделаем». И вот нашей задачей стало собрать миллион переводов.
В 2016 я начал планировать проект по сбору любых тувинско-русских текстов, в 2017-м мы уже презентовали платформу для сбора датасетов. Сейчас модно говорить «датасет», но тогда мы говорили просто «переводы». Собирали тексты на самые разные темы, чтобы переводчик был мощным.
Собрали сначала 100 тысяч, потом 200 тысяч «переводов». На этом остановились, потому что у нас было три гранта: один из них покрыл 30 тысяч переводов, второй — 50, третий — 100.
- Чойган ОндарНаучный сотрудник сектора языкознания ТИГПИ«Али создал специальную площадку, где собирали параллельные фразы. Волонтёры помогали выравнивать тексты, то есть русский — напротив тувинского, чтобы каждое предложение было отдельной строчкой».
Кто возглавил работу?
Мы начали работать с Чойганом — это мой друг из Новосибирска. Вместе учились в НГУ. Я на мехмате, он — на филфаке. Когда он начал в Республике Тыва вести научную деятельность, я его привлёк, мы стали вместе проводить конкурс в Википедии. Организовывали конкурсы по написанию статей на тувинском — в основном про быт, персоналии из XIX—XX вв.еков. Мы с Чойганом проверяли качество перевода. Текстами с конкурса поначалу и пополнили переводческую базу.
Где ещё вы находили материалы с переводом?
Я разговаривал с несколькими сотнями авторов переводов, чтобы они поделились текстами. Кто-то соглашался, я им очень благодарен. Кто-то говорили: «Ой, это же мой труд, как я могу отдать?». Ходил в разные учреждения, очень долго общался.
Люди воспринимали это так: я со своими хотелками вторгаюсь в их рабочие часы, эти часы они защищали. Я пытался им объяснить, что так или иначе мы к этим технологиям придём, и будет лучше, если вы постепенно их изучите, потому что дальше, возможно, на этом будет строиться карьера, будут большие деньги давать, будет нужна экспертиза в компьютерной лингвистике, а вы уже будете разбираться в ней с точки зрения тувинского и русского языков.
Было сложно. В те времена из всех утюгов ещё не говорили про искусственный интеллект, про компьютерные технологии. Я очень сильно уставал вести такие переговоры.
- Чойган ОндарНаучный сотрудник сектора языкознания ТИГПИ«Сначала мы приглашали все организации, которые могли бы в этой работе принять участие. Я составлял график семинаров, ездил в каждую организацию и проводил небольшой мастер-класс, как работу организовать. Али вот создал специальную площадку для сбора переводов. Я показывал, как туда заходить, как добавлять новые фразы, как загружать переводы из Word или Excel».
Из каких же текстов в итоге удалось собрать базу данных?
В первую очередь у нас база состояла из текстов со страниц ВКонтакте, из интерфейса Википедии, текстов с государственных веб-сайтов. Кроме того, из статей Википедии, переводы которых мы делали сами. То ли в 2017-м, то ли в 2018-м нам ещё наконец-то разрешили использовать переводы ТИГИ [Тувинский институт гуманитарных исследований при Правительстве Республики Тыва — прим. «Чернозёма»]. Это были данные из словарей.
Дальше, когда я создал платформу по сбору переводов, мы договорились с волонтёрами, чтобы они туда добавляли собственные переводы. Они их придумывали. По-сути, донатили нам переводами. Большая часть корпуса была собрана за счёт того, что придумывали волонтёры. Иногда сидишь в базе данных, читаешь [добавленные переводы], там иногда смешно, иногда интересно — столько новых вещей узнаёшь!
Ещё были писатели, которые говорили, что перевели такой-то большой труд и дарят его нам. То есть делали всё не один-два человека, а больше десятка. Все проделали огромную работу.
- Чойган ОндарНаучный сотрудник сектора языкознания ТИГПИ«Плюс в Яндексе нас попросили отправить им тувинский монокорпус — тексты только на тувинском языке. Мы отправили 5 миллионов слов, которые сейчас в употреблении. Они были из статей в интернете, из нашей газеты, из статей с правительственного сайта. В Яндексе сразу через месяц или два сделали нам Яндекс.Клавиатуру. В ней появилась функция автозамены».
Помимо личного времени, чем ещё пришлось пожертвовать?
Я по большей части платил за обслуживание серверов и стабильность платформы, куда загружались переводы. Её приходилось постоянно менять для улучшения, добавления функций. Мы выигрывали гранты благодаря участникам нашего проекта, которые учились в Тувинском государственном университете. Замечательные ребята!
Когда денег не хватало или даже были долги, мне приходилось самому платить за переводы. Иногда люди переводили больше, чем у проекта было бюджета, но просили им оплатить, типа, они же всё равно перевели.
В какой-то момент не хватало кучи денег, около 30 тысяч рублей. Просто становилось стыдно перед людьми. Одна девушка делала «переводы» ещё во время декрета, и вот у неё ребёнку уже три года, а деньги мы ей так и не перевели. Прошло столько лет, а мы ведь обещали… Я ей оплатил всё из своего кармана.
Было мало финансирования, держалось всё на личной инициативе. Есть люди, которых я даже не просил, но они сами добавляли переводы. Смотрели, что я во ВКонтакте публиковал про переводчик, и отзывались. Кто-то просто деньги кидал — 10 рублей, 100 рублей.
- Чойган ОндарНаучный сотрудник сектора языкознания ТИГПИ«Работа ещё не закончена. Нам нужно ещё примерно 200 тысяч параллельных фраз собрать, отредактировать и добавить на платформу, чтобы улучшить переводчик. Конечно, для совершенства нет предела, даже англо-русский перевод с каждым годом всё улучшают и улучшают. То есть эта работа практически бесконечная. Но если мы сейчас это не сделаем, то потом всё может забыться, и уже никто не будет доделывать».
глава 3
Интерес Корпораций

Платформа tyvan.ru для загрузки тувинских переводов
Почему Яндекс решил пойти вам навстречу? Что привлекло их в вашем проекте?
С Яндексом мы начали работать из-за того, что [в 2022 году] ООН объявила декаду языков коренных народов. Соответственно, в России прошли тематические мероприятия, практически во всех регионах были активности. Некоторые институты власти, по-моему, Минкульт, Федеральное агентство по делам национальностей (ФАДН) взяли на себя часть функций по развитию языкового многообразия. И они, мне кажется, хотели, чтобы какой-то бизнес, работающий с информацией, СберБанк или Яндекс, подключился к этой теме.
Отвечая на ваш вопрос, лучше всего сказать — так совпало.
Помимо меня, в России несколько тысяч прекрасных программистов, филологов, все много лет занимались коренными языками. И в тот момент их труды стали востребованы на государственном уровне.
Естественно, все начали вкладываться. В Тувинском институте гуманитарных исследований Чойган стал ответственным за то, чтобы интеграция тувинского языка в Яндекс была плавной, он вёл с компанией переговоры от имени института.
- Чойган ОндарНаучный сотрудник сектора языкознания ТИГПИ«На одном из форумов в декабре 2022 года я представлял доклад о планах цифровизации тувинского языка. Помимо меня, там были и другие активисты из Башкортостана, Коми, много народа было. Каждый читал доклад о том, как оцифровать свой язык. Тогда у Федерального агентства по делам национальностей, у Тимура Гомбожаповича Цыбикова и у других возникла идея — это всё организованно сделать, пойти по каждому пункту. Первым таким большим проектом стало включение языков народов России в Яндекс.Переводчик.
Тогда, по-моему, в 15 национальных республик, в том числе в Республику Тыва, главам субъектов были разосланы письма с просьбой назначить ответственного от республики, кто войдёт в рабочую группу, и найти финансирование на проект. Мы с директором Агентства по Науке Республики Тыва вошли в рабочую группу, и с тех пор нам помогают. В 2024 году мы выиграли грант на 800 тысяч рублей. Участвовать изъявили желание где-то 15−20 организаций Республики Тыва: Национальная библиотека, Детская библиотека, Музей, Архив, конечно же, наш Тувинский государственный университет, Союз писателей Республики Тыва, Совет молодых учёных, ещё Институт развития национальной школы и так далее. И примерно за эти два года мы собрали ещё около 407 тысяч параллельных фраз. Но работа состояла не только в их сборе, но и в редактировании, переводе. Ещё Яндекс прислал нам свой корпус параллельных англо-русских фраз — нужно было их тоже перевести, 100 тысяч фраз с русского на тувинский».
В прошлом году тувинский язык появился ещё и в Google Translate. Это тоже было связано с вашими трудами?
Да, это наши датасеты. В конце 2023 года у нас было уже 100 тысяч или даже больше проверенных переводов. Я их отсортировал, обработал через скрипты — очистил от странных символов. И написал разработчику в Google, что у меня есть датасет, давайте добавим тувинский язык, потому что в Республике Тыва большинство пользуются Android, для них это важно. Меня попросили удостовериться, что переводы у нас без авторских прав. Так у нас и было. Google всё подошло, мне сказали: «Ждите полгода, выпустим». А уже летом 2024-го выходит переводчик, супер!
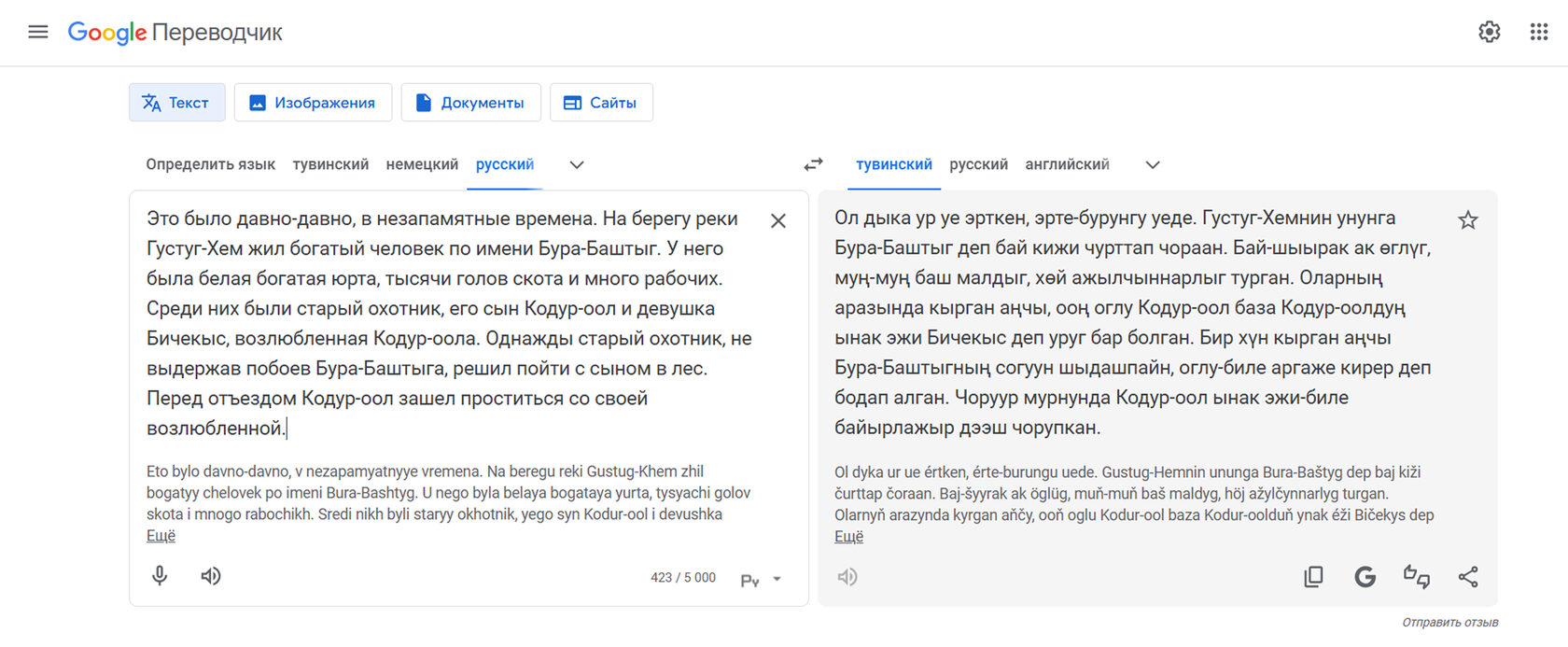
Пример перевода фрагмента тувинской сказки «Кондур-оол и Биче-кыс» в Google Translate
Как вы убеждались в том, что переводы не были защищены авторским правом?
Принято, что когда люди публикуют в датасетах свои данные, то они несут определённую ответственность, они честные. Нечестные люди не захотят этим заниматься, тратить кучу времени. Да, есть отдельные кадры, занимающиеся троллингом, но их выявляют так или иначе.
Когда я брал у людей переводы, подразумевал, что те, с кем я работаю — честные, что они берут тексты или фразы без авторских прав. Если видел, что взято из книги и её авторы с нами об этом не говорили, тогда откладывал.
Почему нельзя использовать переводы с авторским правом? Они ведь идут только на обучение переводчика.
В международном праве очень ценится понятие авторского права. Из-за него в каких-то странах люди вообще даже близко не хотят подходить к компьютерной лингвистике. Начинают работать только если видят, что всё безопасно.
В России об авторском праве много говорили википедисты: давайте стараться искать авторов, когда публикуем что-то, когда люди репосты делают. Старались пометить, указать авторство. Классная мировая практика, хорошая и честная. Сейчас люди уже стали так делать, но всё ещё недостаточно.
Яндекс старается в том же ключе работать. Я думаю, все компании к этому придут, потому что народ становится всё более грамотным. Сразу идут в суд. Особенно блогеры любят такое: «Вы меня скопировали, меня не указали». Сразу подают иск.
глава 4
Как работать с болью

Памятные значки, сделанные самими участниками проекта по внедрению тувинского языка в Яндекс.Переводчик. Фото со страницы Эллады Аннай в VK
Вы, возможно, замечали — появление в Яндекс.Переводчике тувинского языка в некоторых кругах вызвало неоднозначную реакцию. Звучали претензии: а почему не добавили другие языки. Как думаете, откуда взялся такой негатив?
Думаю, это всего лишь боль, и люди не знают, как с этой болью работать. Тут стратегия такая — давайте думать, как сделать. Только сказать: «Нам не дали» — недостаточно. Можно сказать: «Нам не дали, а давайте что-то делать, придём к нашим учёным, организуем конференцию». Прийти к Министерству образования, сказать. Ограничиваться только болью — плохо, надо искать решение.
У всех получится собрать датасет, потому что в открытом доступе уже есть столько книг, трудов, текстов во ВКонтакте, в других соцсетях пишут люди. Всё это можно скопировать. И поощрять людей, чтобы они загружали новые тексты. Можно придумать инструменты, как делиться текстом, создавать базу данных для переводчика. Человек, допустим, соглашается, нажимает галочку, и бот копирует со страницы в социальной сети данные на бурятском. Получается, тупо нужны программисты, филологи, волонтёры, переводчики, журналисты — и всем вместе работать.
- Чойган ОндарНаучный сотрудник сектора языкознания ТИГПИ«Торжественная премьера тувинского языка в Яндекс. Переводчике состоялась 3 апреля 2025. Мы тогда наградили всех волонтёров, всех, кто участвовал. Выдали благодарственные письма от Министерства образования Республики Тыва, книги. Где-то 25 человек, которые внесли 5000 предложений и более, получили значки [с брендом Яндекса]. Кстати, сначала Яндекс был против, что мы используем его логотип, но, когда я сказал, что мы уже всё сделали, они согласились.Всего проекте тувинского переводчика участвовали около 460 человек, включая тех, кто всего по одной фразе прислал. Более ста фраз — внесли 170 человек. Они будут указаны как авторы этого параллельного корпуса. Больше всех внесла одна девушка — 39 000 фраз. Это практически норма для целых организаций».
Как должны выглядеть первые шаги тех, кто решил добавить свой язык в онлайн-переводчик?
Сейчас требований к добавлению языка в Яндекс. Переводчик стало меньше. Не миллион «переводов» явно. Может быть, 30 или 50 тысяч.
Что нужно сделать? Нужно сформировать или скопировать базу данных параллельных переводов. Есть два способа. Во-первых, можно попросить Яндекс: «Киньте, пожалуйста, датасет, который вы передавали тувинским филологам, или ещё какой-нибудь». Они могут дать. Это делается через диалог напрямую с Яндексом или с ФАДН.
Во-вторых, можно работать с населением. Например, создать в Telegram чат-бот, в который люди смогут кидать свои тексты на бурятском. И ещё другой чат-бот — для переводов этих текстов. Боты сейчас очень развиты, с ними можно работать.

Чойган Ондар и другие участники проекта на презентации тувинского языка в Яндекс.Переводчике. Фото со страницы Чойгана Ондара в VK
Первостепенная задача — собрать банк переводов. 10, 60, 100 тысяч переводов. Когда будет 100 тысяч, я думаю, можно просить Яндекс даже без бета-версии запускать. Думаю, прямо сейчас собрать бурятские тексты и перевести — вообще не проблема.
Несколько вариантов, как это можно организовать. Первый — скинуться деньгами, найти человека-переводчика, которому вы будете платить за то, что он переводит тексты для базы данных. Второй — привлечь как можно больше разных людей. Преимущества обоих вариантов совершенно разные. При первом — работает ограниченное количество профессионалов, о проекте знает мало людей, и только узкий круг озадачен этим. Мастерство будет прокачиваться только у них.
Второй сценарий даёт больше преимуществ в социуме. Чем больше людей вовлечены, тем больше эмпатии к проекту. На выходе все будут так или иначе довольны. Ещё плюс — в будущем будет больше компьютерных лингвистов.
- Чойган ОндарНаучный сотрудник сектора языкознания ТИГПИ«Лучше всего собирать свой корпус из текстов, переведённых профессиональными переводчиками, начиная с того момента, когда были утверждены какие-то орфографические правила. У нас орфографические правила современного тувинского языка утвердились где-то в 1963 году, и мы брали тексты, которые выходили после 1963 года. Это важно, потому что должно быть единообразие. А у некоторых народов до сих пор идут споры по поводу правил в языке. И дело даже не в диалектах. Например, горномарийский и язык луговых мари — оба диалекта включили в переводчик. А бывает так, что у каждого представителя народа свои правила для языка. Одна газета вот так пишет, другая по-другому. Для них цифровизация стала практически нереальной проблемой».
глава 5
Что дальше

Нейросетевая иллюстрация Али Кужугета для его обработки тувинской сказки. Фото со страницы Али Кужугета в VK
В последнее время в разных регионах, в частности в Удмуртии, много советских или даже дореволюционных произведений переводят с помощью ИИ. Тем самым возрождают эти книги, делают вновь актуальными.
Да, это очень хорошее стечение обстоятельств. Люди стали продуктивнее, чем в прошлом. И больше своей продуктивности стали уделять творчеству. Ну, и, естественно, своей культуре. Начинают производить музыку, фильмы, тексты. Эти же люди их потребляют, несут деньги. А экономика, в свою очередь, видит, что люди производят кучу всего, деньги крутятся, государство получает дополнительную финансовую выгоду. Регионам важно внутреннее потребление. Газ и нефть исчезнут, а вот эти интеллектуальные продукты останутся. Я верю, что регионы могут развиваться в таком ключе.
Продолжите ли дальше работать с тувинским языком? Какие ещё есть направления для его развития?
- Чойган ОндарНаучный сотрудник сектора языкознания ТИГПИ«Сейчас мы будем работать над развитием голосовых технологий Яндекса, создавать синтезатор тувинской речи, благодаря которому Яндекс будет говорить на тувинском, озвучивать содержание сайтов. Для самого Яндекс. Переводчика тоже нужен синтезатор, чтобы озвучивать фразы. Второй блок работы — создание распознавателя, чтобы нейросети Яндекса понимали тувинский на слух. Эти два проекта мы сейчас начали, но там свои сложности. В первую очередь нужна хорошая звукозаписывающая студия. В принципе, у нас в институте есть студия, где озвучивают фильмы, но, к сожалению, она не подходит под требования Яндекса. Будем искать другие студии в Кызыле. Если не найдём, придётся Яндексу самому искать студию где-то в Москве. Но будет сложно туда приводить профессиональных тувинских дикторов, артистов. Для распознавателя речи нужно таких человек 20. Женские голоса, мужские».
Мы пришли к тому, что понадобится включение и других технологий. Я сделал такую презентацию в виде цветочка — в ней показал, как для тувинского языка могут развиваться языковые технологии в ближайшие 10 лет. Там в каждом лепестке была технология. Перевод клавиатуры, распознавание аудио, синтезация речи… Это так или иначе стало выполняться.
Такие технологии нужно сделать один раз для каждого языка, и потом все смогут ими пользоваться. Файл конфигурации с правописанием русского языка для Word не менялся с 2015 года. Он просто кем-то написан, и всё, его никто не трогает. Мы что-то в Word пишем, и он нам подсказывает, где в словах ошибки. Такие технологии нужно поддерживать в рамках обязательств регионов перед своими уставами, конституциями.
Сейчас было бы здорово нашим филологам перейти к звуковым технологиям, чтобы постепенно Алиса от Яндекса заговорила на тувинском. Будет классно, когда родители смогут сказать умной колонке: «Расскажи моим детишкам сказочку на тувинском».
Люди должны эту технологию использовать для вдохновения, для чувств, чтобы просто жить радостно. Думаю, что в России это очень востребовано.
06.06.2025
Спасибо, что дочитали до конца!
Понравился текст? Считаете эту тему важной? Тогда поддержите его создателей — айда к нам на Boosty!
хочу помочь Чернозёму
Спасибо,что дочитали до конца!
Карта сайта
Контакты
информация






